Digit Recognition using Speech Spectrograms
ProjectDigit classification based on speech has emerged as a crucial component in voice recognition technologies. Here we recognize spoken digits through the application of audio processing and machine learning methodologies. Contemporary voice-activated systems, such as Google Assistant and Siri, significantly depend on these algorithms to accurately interpret spoken instructions. Speech signals, being inherently non-stationary, necessitate segmentation into shorter, quasi-stationary frames for effective processing. Utilizing spectrograms—visual depictions of frequency content over time—facilitates targeted analysis of speech signals. This method effectively extracts features, especially when used with supervised machine learning techniques like artificial neural networks (ANNs). Studies have shown that multi-layer perceptrons (MLPs) excel in classification by understanding complex, non-linear relationships between features and labels. The emergence of deep learning has markedly enhanced the field of spoken digit recognition. Convolutional Neural Networks (CNNs) have shown exceptional accuracy within this area. By transforming audio signals into spectrograms—a visual representation of frequency spectra over time—CNNs can adeptly learn spatial hierarchies of features, resulting in superior recognition performance.
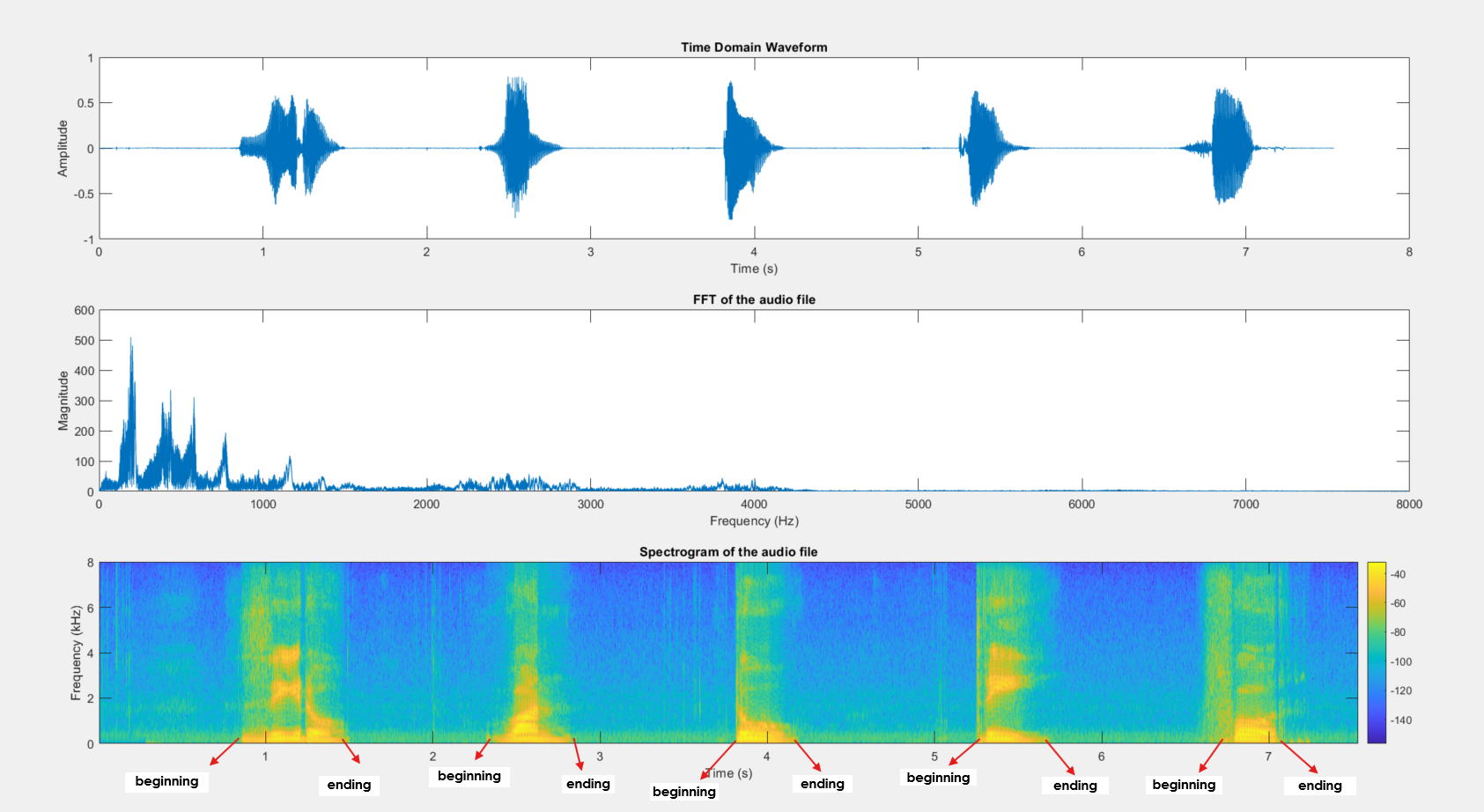
Visualization of Clean speech audio file
The generated spectrogram reveals yellow areas where strong energy is present in the 0 to 2-4 kHz range, indicating vowels, which are represented by bright, continuous bands in the lower frequency range due to the open vocal tract that produces this sustained energy.
The fundamental frequency for the first vowel is around 200 Hz, which is visible at the lower end of the frequency axis where the energy is concentrated.
The time-domain plot shows the variations in the amplitude of the speech signal over time, and the FFT plot displays the dominant frequencies, which is helpful for understanding the overall frequency behavior of the signal. The spectrogram shows the localized frequency information over time. By identifying the brighter regions, you can differentiate between vowels and other speech sounds since vowels typically have sustained energy at specific frequencies.
We then move on to train a deep learning model on clean and noisy audio file spectrographs. The confusion matrices are shown below.
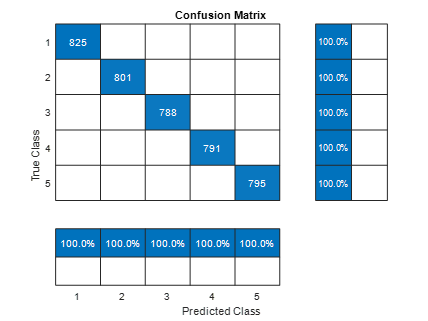
Confusion Matrix for Clean speech audio file
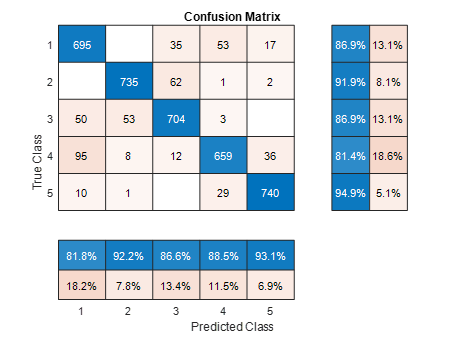
Confusion Matrix for noisy speech audio file
The results showed the impact of data quality on neural network performance. The model achieved a high unrealistic accuracy of 100% on clean data, indicating effective feature learning, but accuracy dropped to around 88.33% when noise was introduced, showing how a noisy dataset can change the perception. Confusion matrices revealed that while clean data predictions mostly aligned along the diagonal, indicating correct classifications, noisy data produced increased misclassification rates, with certain digits being confused more frequently. We learn here the important role of data preprocessing techniques to enhance the model performance. Analyzing confusion matrices also provided insights for targeted model improvements and data collection efforts to tackle specific classification challenges.
This study successfully showed that recognizing spoken digits can be done by using speech spectrograms and machine learning techniques. We initially transformed speech signals into spectrograms to capture the key frequency and timing information needed for digit classification. However, once we added noise, it significantly affected the model’s performance, reducing its accuracy from an ideal 100% down to 88.33%. This drop showcases how important data quality and preprocessing are for building effective speech recognition systems. Finally, the confusion matrices revealed specific parts where noise led to misclassifications.